1 分类
1.1 混淆矩阵
- True Positive(真正, TP):将正类预测为正类数.
- True Negative(真负 , TN):将负类预测为负类数.
- False Positive(假正, FP):将负类预测为正类数 → 误报 (Type I error).
- False Negative(假负 , FN):将正类预测为负类数 → 漏报 (Type II error).
关系如下表所示:
| 预测值=1 | 预测值=0 | |
|---|---|---|
| 真实值=1 | TP | FN |
| 真实值=0 | FP | TN |
1.1.1 准确率 Accuracy, ACC
$$
ACC(Accuracy) = \frac{TP+TN}{TP+TN+FP+FN}
$$
注:在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc 也有 99% 以上,没有意义
1.1.2 精确率 或 查准率 Precision, P
$$
P=\frac{TP}{TP+FP}
$$
注: 精确率(precision)和准确率(accuracy)是不一样的
1.2.3 召回率 或 查全率 Recall, R
$$
R=\frac{TP}{TP+FN}
$$
1.2.4 F1 测量值
$$
\frac{2}{F1} = \frac{1}{P} + \frac{1}{R} \
F1 = \frac{2TP}{2TP + FP + FN}
$$
注: F1 是精确率和召回率的调和均值
1.3 AUC
AUC 是 ROC (Receiver Operating Characteristic) 曲线以下的面积, 介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
1.3.1 ROC 曲线
这里不赘述ROC的一些细节,参考ROC和AUC介绍以及如何计算AUC
ROC曲线关注两个指标:
$$
truepositiverate: TPR = \frac{TP}{TP + FN}\
falsepositiverate: FPN = \frac{FP}{FP + TN}
$$
ROC 曲线如图(a)所示,横坐标是false positive rate, FPN, 纵坐标是true positive rate, TPR
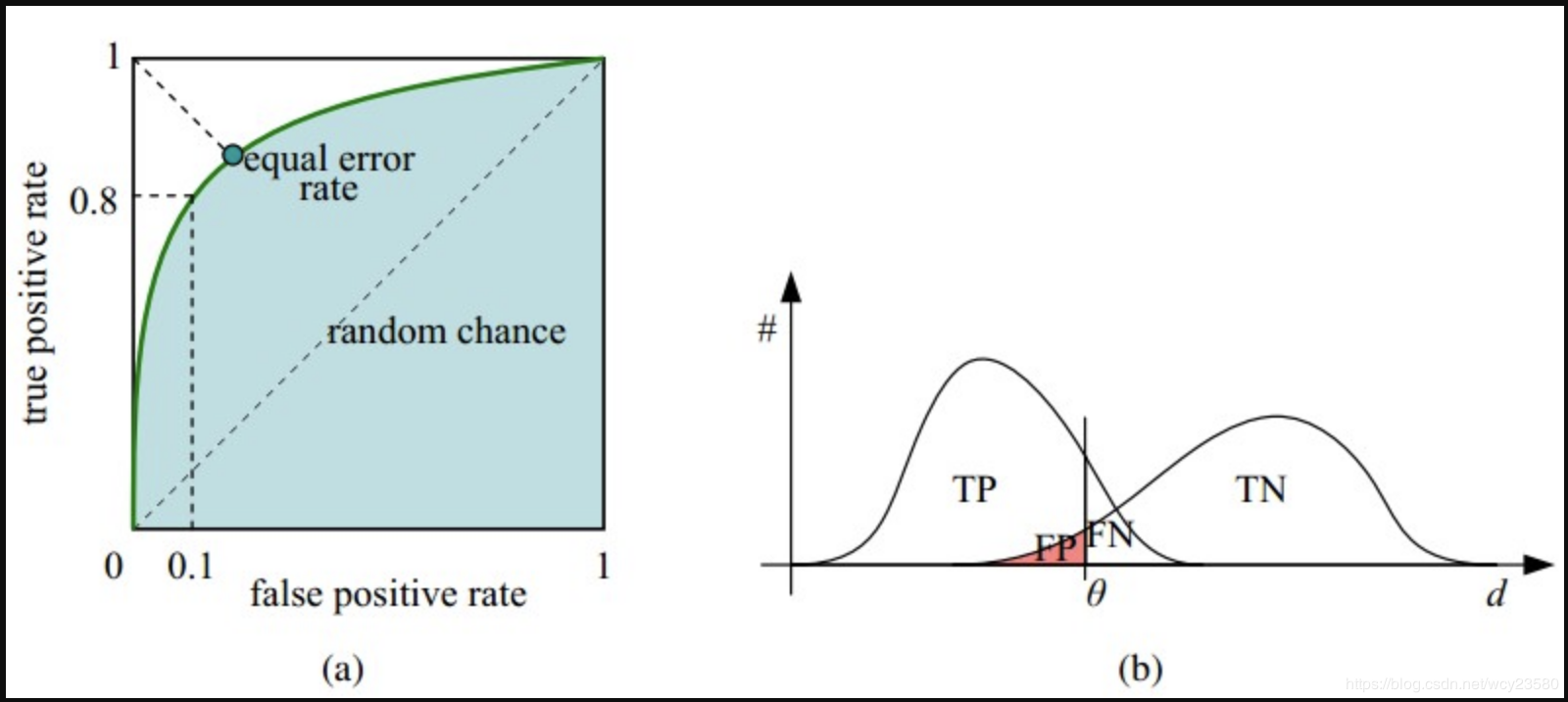
- 横轴FPR:$1-TNR$, $1-Specificity$,$FPR$越大,预测正类中实际负类越多。
- 纵轴TPR:$Sensitivity$(正类覆盖率), $TPR$越大,预测正类中实际正类越多。
- 理想目标:$TPR=1$,$FPR=0$, 即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,$Sensitivity$、$Specificity$越大效果越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
简单说:AUC值越大的分类器,正确率越高:
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC=0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC<0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在 AUC<0.5 的情况。
1.3.2 为什么要使用ROC曲线 和 AUC 评价分类器
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比: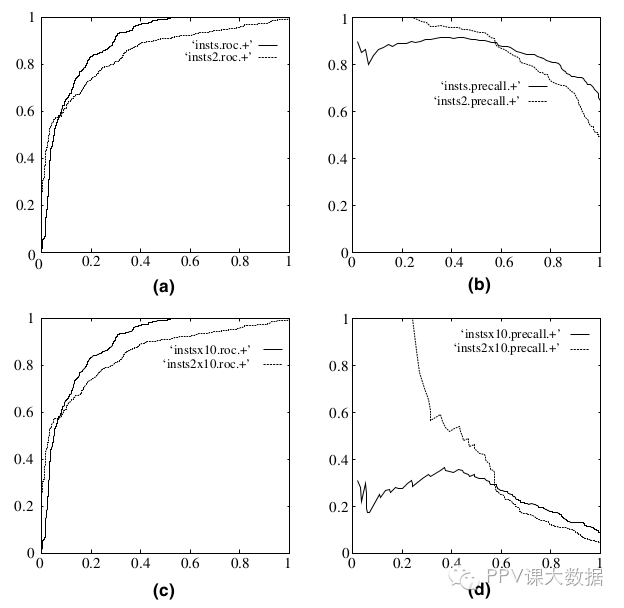
- (a)和 (c)为Roc曲线,(b)和(d)为Precision-Recall曲线。
- (a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
2 回归
2.1 平均绝对误差
平均绝对误差$MAE$ (Mean Absolute Error) 又被称为 $l1$ 范数损失($l1-norm~loss$):
$$
MAE(y,\hat{y}) = \frac{1}{n} \sum_{i=1}^{n}|y_i−\hat{y_i}|
$$
2.2 平均平方误差
平均平方误差 $MSE$ (Mean Squared Error) 又被称为 $l2$ 范数损失($l2-norm~loss$):
$$
MSE(y,\hat{y}) = \frac{1}{n} \sum_{i=1}^{n}|y_i−\hat{y_i}|^2
$$




